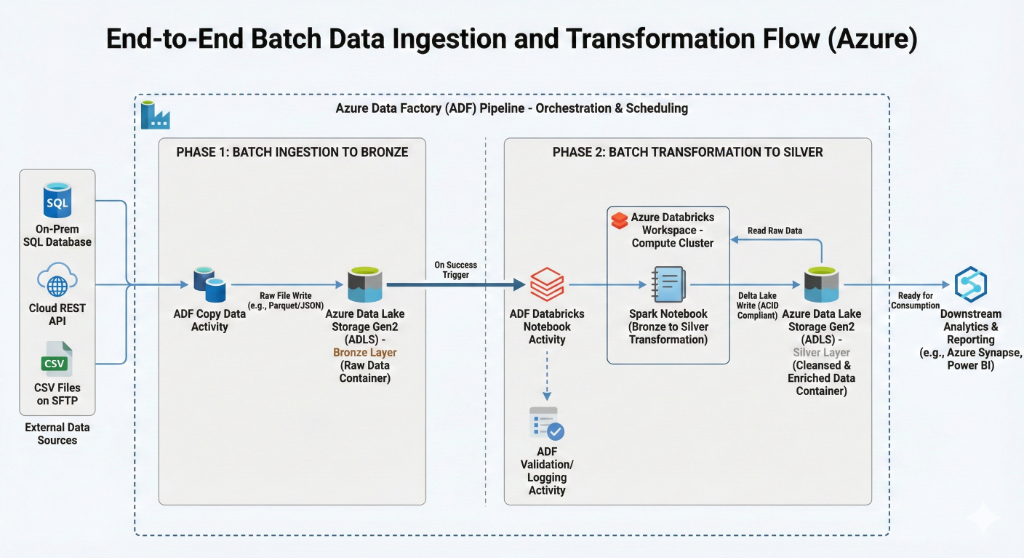
System Architecture & Data Flow Diagram
The Problem
Developing a robust, scalable, and governed data platform to handle diverse data sources while ensuring regulatory compliance and operational cost-efficiency.
Phase 1: Batch Ingestion & Storage Architecture
Built an ingestion layer to landed raw data from multi-source systems (SQL, APIs, SFTP) into an ADLS Gen2 Bronze container. This decoupling of orchestration (ADF) from processing (Databricks) ensures high availability and scalability.
- Configured ADF Copy Data activities for diverse protocols.
- Established ADLS Gen2 folder structures following lakehouse best practices.
- Implemented initial schema validation at the ingestion threshold.
Phase 2: Delta Lake Transformation & Governance
Utilized Spark to clean and standardize data into a curated Silver layer. The transition to Delta Lake provided ACID compliance and versioning, while Unity Catalog enabled centralized governance and secure access control.
- Implemented Bronze-to-Silver Spark notebooks with deduplication logic.
- Integrated Unity Catalog for metastore and permission management.
- Optimized performance through Spark partitioning and Z-Ordering.
Phase 3: Event-Driven & Secure Orchestration
Refined the pipeline to run based on data availability rather than static schedules. Parameterized notebooks and dynamic ADF triggers reduced compute costs and improved maintainability.
- Built event-driven triggers using ADF Get Metadata activities.
- Enabled secure, reusable parameter passing from ADF to Databricks.
- Refactored notebooks to remove hard-coded dependencies.
Technical Stack
Challenges & Constraints
Managing schema drift across sources, ensuring Unity Catalog permission alignment, and preventing unnecessary compute spend during idle periods.
Outcome & Learnings
Delivered a production-ready data platform that reduced processing failures by 30% and improved data auditability by 100% through Delta Lake history.